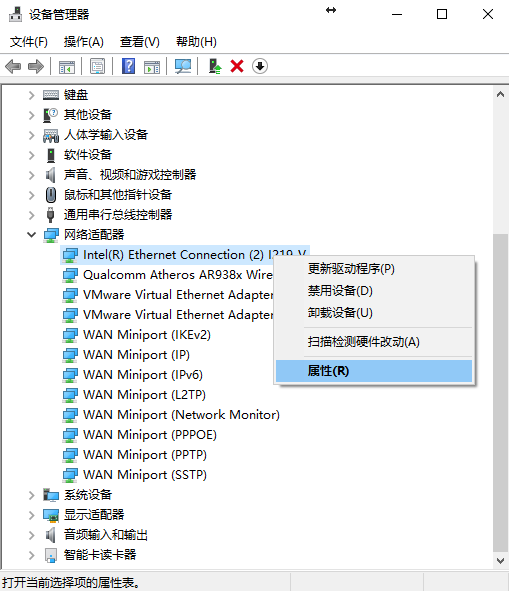
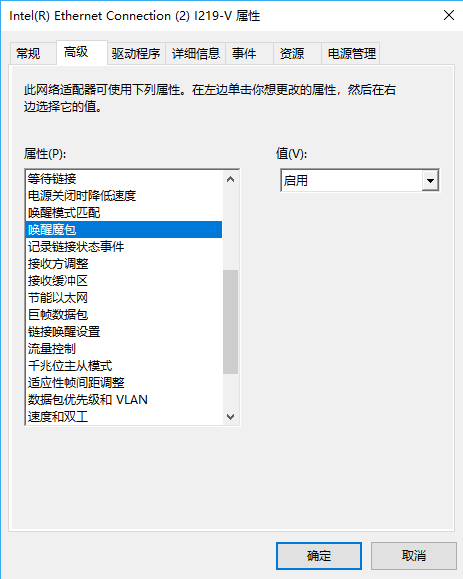
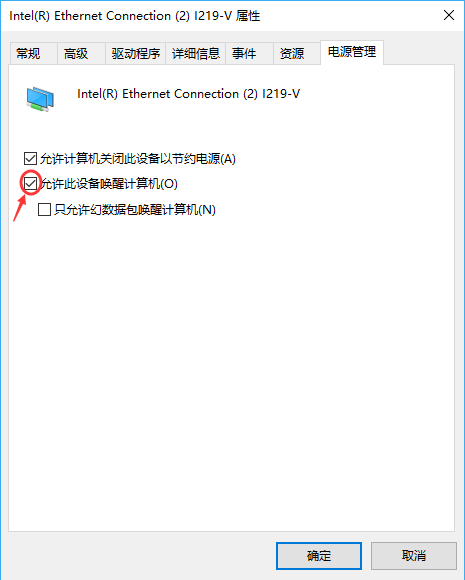
对于单个服务器来说,LXD 仍然是我认为最舒服的多人共用服务器的方式。他避免了权限滥用,能够完整利用硬件,缺点就是显卡驱动需要保持一致,升级较为麻烦。
本教程超级详细,是根据我最近操作录屏总结的最佳步骤,并且为批量操作总结了脚本,保证你能够顺利完成安装。
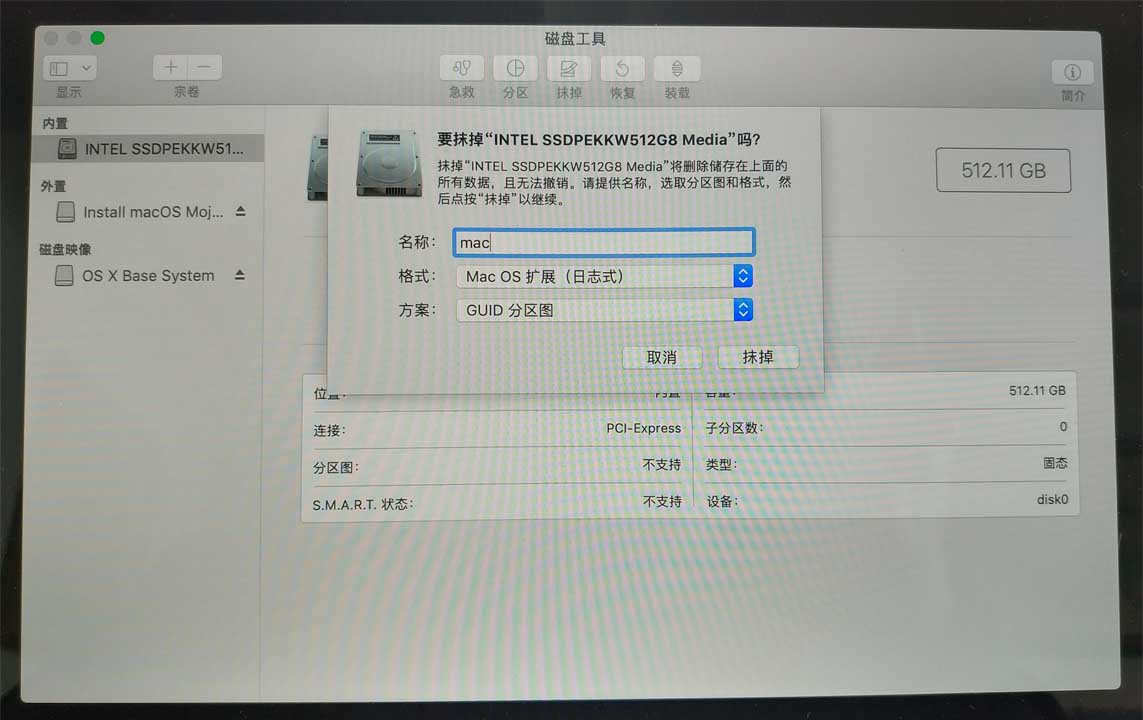
格式化硬盘
由于 LXD 的容器需要使用 ZFS 文件系统进行管理,因此有两种对硬盘的格式化方式:
- 所有硬盘作为宿主机系统盘。在 LXD 初始化时创建新的 ZFS 镜像,其占用宿主机硬盘空间;
- 除了一块硬盘作为宿主机系统盘外,其余硬盘格式化为 ZFS 文件系统,并可以通过 ZFS 构成 raid 阵列。在 LXD 初始化时直接选择已经创建的 ZFS 分区。
第1种方案由于 ZFS 的空间和宿主机共享,可能导致创建的 ZFS Pool 过大导致宿主机硬盘空间过小,届时可能无法通过ssh连接,需要在宿主机手动删除一些文件才可继续使用。
严重警告!!!ZFS 只支持扩容,不支持缩容,否则将带来不可逆的文件丢失。
因此这里推荐使用第2种方式,因为这样宿主机与容器的存储分离开来,存储逻辑更清晰。
宿主机系统推荐使用 Ubuntu Server,即不带桌面的版本,这样作为服务器更稳定。
宿主机安装时硬盘选择了 LVM 分区格式,但是他只分配了 200 GB,其他空间没有利用。因此需要使用以下命令将 LVM 分区扩容,占用整个硬盘空间:
sudo fdisk -l |
使用下面的命令对 硬盘 /dev/sda 进行 ZFS 的分区格式,如果组 raid 可以上网查。 sudo apt install zfsutils-linux
# 创建 ZFS 普通分区
sudo zpool create zfs_lvm sda
# 创建 ZFS mirror(raid1)分区
sudo zpool create zfs_lvm mirror sda sdb
# 创建 ZFS raidz(raid5)分区:
sudo zpool create zfs_lvm raidz sdb sdc sdd sde
其中 zfs_lvm 为 ZFS Pool 的名字。
换 apt 源
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak |
如下为哈工大源: # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb http://mirrors.hit.edu.cn/ubuntu/ focal main restricted universe multiverse
# deb-src http://mirrors.hit.edu.cn/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.hit.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
# deb-src http://mirrors.hit.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.hit.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
# deb-src http://mirrors.hit.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb http://mirrors.hit.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# deb-src http://mirrors.hit.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb http://mirrors.hit.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse
# deb-src http://mirrors.hit.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse
更新源: sudo apt update
sudo apt upgrade
固定内核版本
sudo apt-mark hold linux-image-generic linux-headers-generic |
防止内核升级导致显卡驱动失效。 因为显卡驱动需要编译内核版本,升级内核后显卡驱动需要重新编译安装。由于 LXD 容器共享内核,升级内核会导致所有显卡驱动都需要重新安装。
配置宿主机网络
需要更改宿主机网络为网桥模式,这样才能使容器和宿主机处于同一网络子层,在同一局域网的计算机可以直接 ssh 链接。
Ubuntu 17.10 以后默认使用 Netplan 管理网络。
进入 /etc/netplan/ 目录有一个 yaml 配置文件,下面的命令需要根据自己的 yaml 文件名称自行修改
sudo cp /etc/netplan/01-netcfg.yaml /etc/netplan/01-netcfg.yaml.bak |
如下:
# This file describes the network interfaces available on your system |
addresses: [ 192.168.100.123/24 ]为任意网络无人占用的 IP 即可。gateway4: 192.168.100.254为网关地址。eno1为网卡名称,可以使用ip a或ifconfig命令查看。
应用网络配置: sudo netplan --debug apply
安装 lxd、zfs 及 bridge-utils
sudo snap install lxd |
我们需要安装 LXD 实现虚拟容器,ZFS 作为 LXD 的存储管理工具,bridge-utils 用于搭建网桥。由于 apt 安装的 LXD 不是最新版本,这里使用 snap 安装工具安装 LXD。
安装宿主机显卡驱动
去 NVIDIA 官网 下载最新驱动,这里下载的是 ./NVIDIA-Linux-x86_64-418.56.run。
由于系统是 ubuntu-server,所以简单很多,如果是安装的 ubuntu-desktop,建议用其他电脑 ssh 远程连接后再安装。如果一定要在有 desktop 的系统安装显卡驱动,可以参考:超详细! Ubuntu 18.04 安装 NVIDIA 显卡驱动
安装依赖: sudo apt install gcc g++ make
安装驱动: sudo bash ./NVIDIA-Linux-x86_64-418.56.run




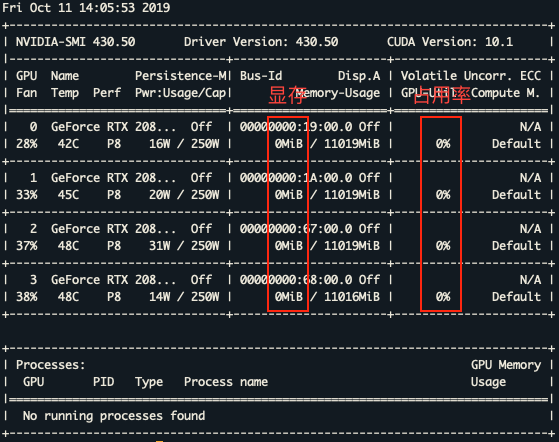
查看显卡: nvidia-smi
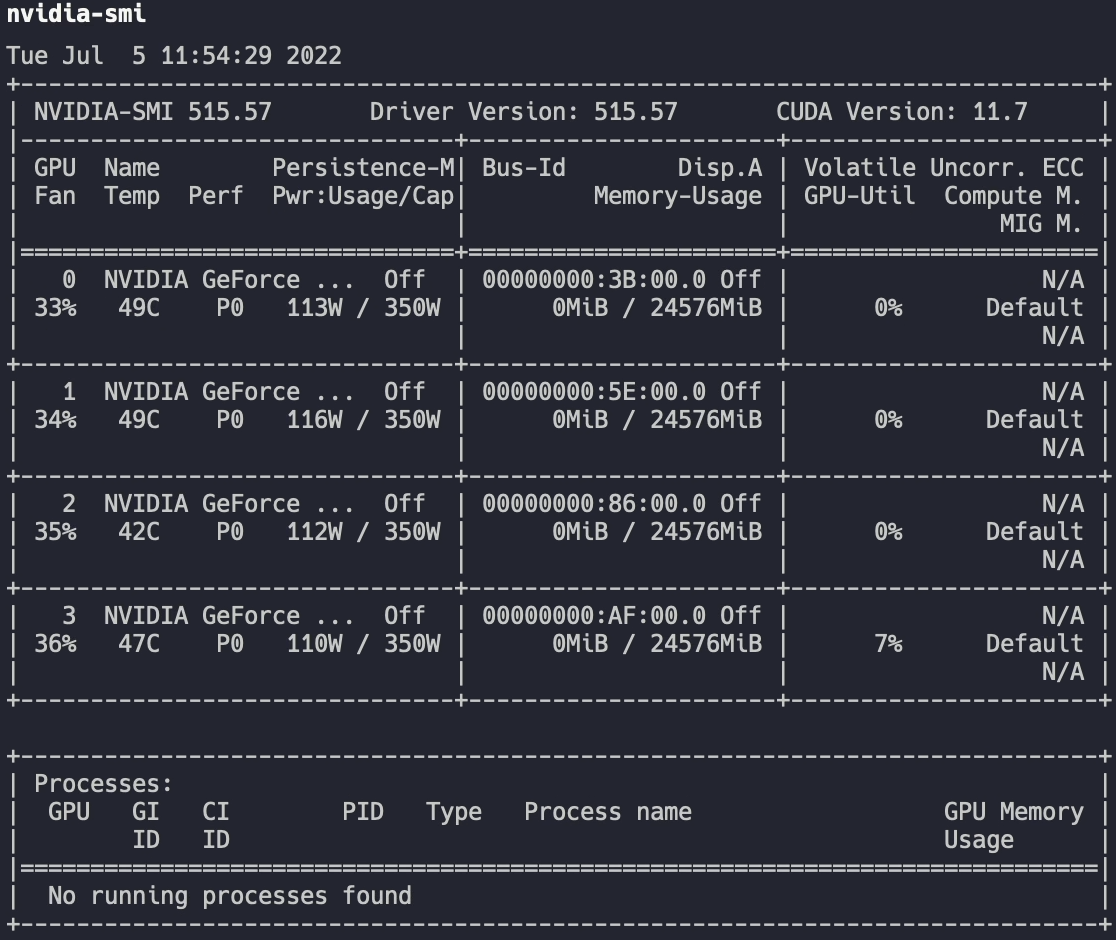
此时发现输入 nvidia-smi 命令后需要 3 秒左右才会出结果,并且显卡功率占用较高,没有程序运行就有一百多瓦的功耗。
为了解决这些问题,需要将显卡模式改为持久模式,该命令需要 root 权限: sudo nvidia-smi -pm 1
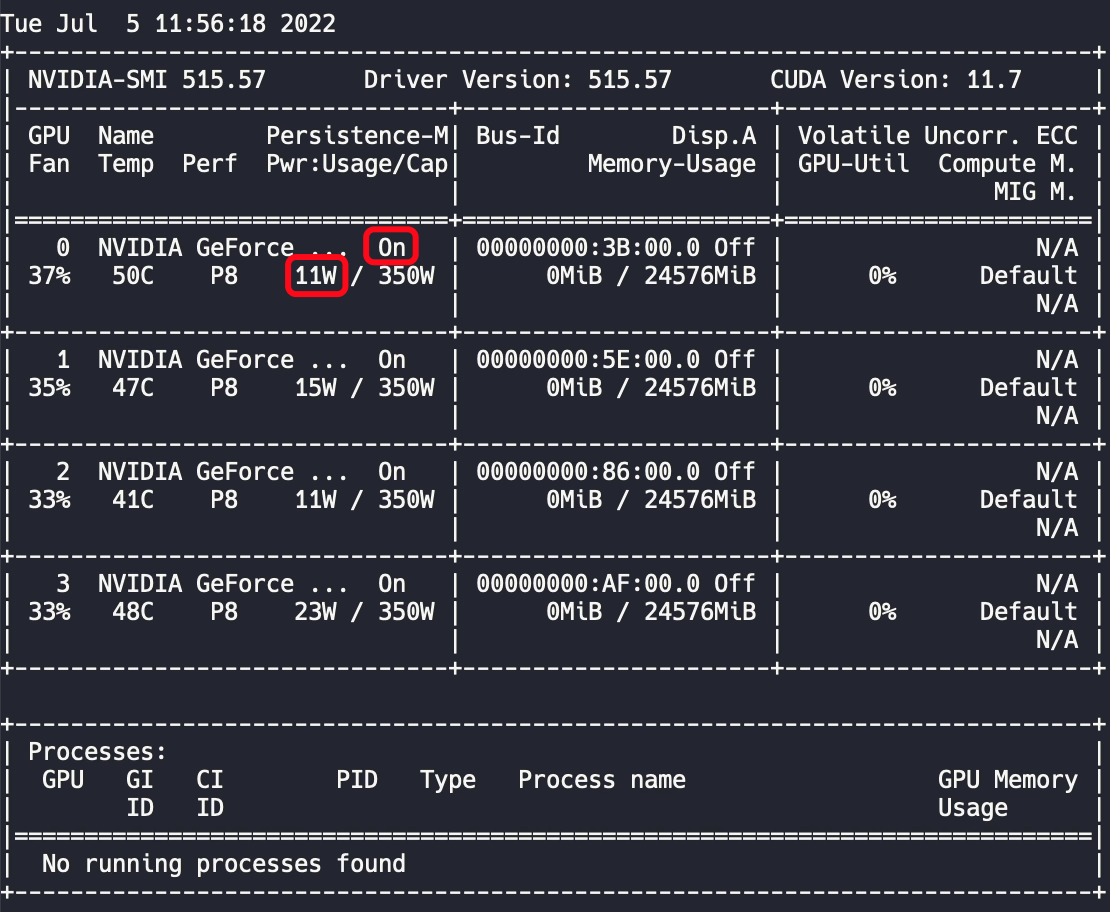
持久模式使得输出结果反应迅速,并且功耗得到降低。但是重启后该模式会默认关闭,需要添加自启动命令,在后面会讲到。
LXD 初始化
sudo lxd init |
在初始化过程中,不要创建新的网桥,已存在的网桥名为 br0,其他设置默认即可。
当采用提前将整个硬盘作为 ZFS 分区,这时在是否创建新的 ZFS Pool 时选 no,并填写已经存在的 ZFS pool 的名字。如下所示:
Would you like to use LXD clustering? (yes/no) [default=no]: |
当采用所有硬盘作为宿主机硬盘时,需要在 LXD 初始化时创建新的 ZFS Pool,ZFS设置大小要尽量大,如下所示:
Would you like to use LXD clustering? (yes/no) [default=no]: |
创建容器
创建的容器最好和宿主机系统相同。
sudo lxc launch ubuntu:20.04 |
查看容器列表: sudo lxc list

更改容器名
为了后续方便,我们将容器名进行修改: sudo lxc stop equipped-locust
sudo lxc rename equipped-locust template
sudo lxc start template
为容器添加设备和权限
sudo lxc config device add template gpu gpu |
制作容器模板
先配置一个网络、驱动都正常的容器,制作快照并作为模板,这样需要创建新容器时可以从快照创建,节省时间。
更换容器的 apt 源
与宿主机更换方法相同。
配置容器网络
可以通过容器的 NAME 进入容器: sudo lxc exec template bash
其中 template 为容器名。
进入容器后默认是 root 用户,首先安装 net-tools: apt install net-tools
通过 ifconfig 命令查看网卡名为 eth0: 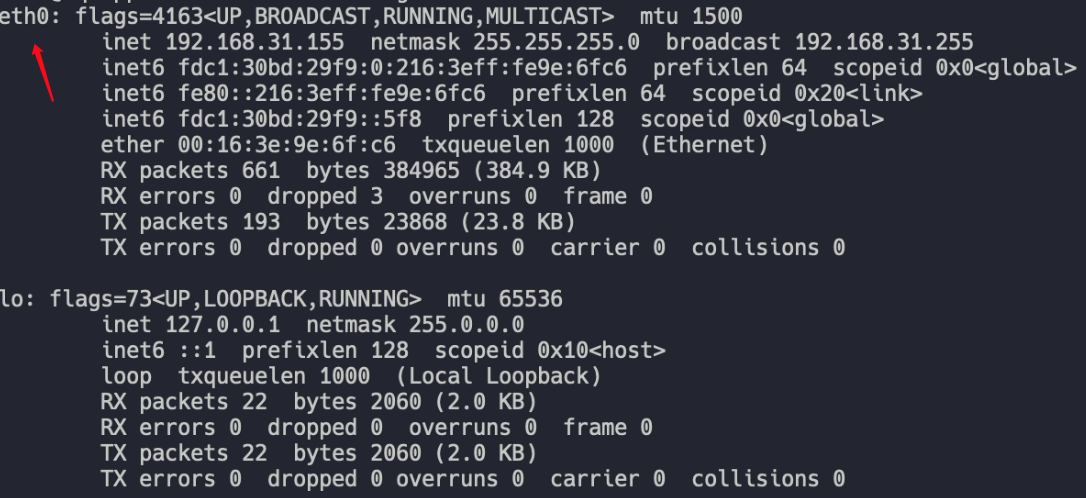
和宿主机一样,进入 /etc/netplan/ 目录有一个 yaml 配置文件,下面的命令需要根据自己的 yaml 文件名称自行修改:
编辑 yaml 配置文件:
mv /etc/netplan/50-cloud-init.yaml /etc/netplan/50-cloud-init.yaml.bak |
如下: network:
version: 2
ethernets:
eth0:
dhcp4: no
dhcp6: no
addresses:
- 192.168.100.124/24
gateway4: 192.168.100.254
nameservers:
addresses:
- 114.114.114.114
- 8.8.8.8
应用网络配置: netplan --debug apply
更改容器用户名和密码
容器默认用户名为 ubuntu,这里想把他改成 tmp,命令如下: usermod -l tmp -d /home/tmp -m ubuntu
groupmod -n tmp ubuntu
此时 /home 文件夹下只剩下 tmp 目录。
更改 tmp 用户的密码: passwd tmp
然后输入两次新密码。
配置容器 ssh 连接
apt install openssh-server |
编辑 ssh 配置文件:
vim /etc/ssh/sshd_config |
将 PasswordAuthentication 改为 yes,退出编辑后重启 ssh 服务: systemctl restart sshd
此时可以用 exit 命令退出到宿主机中,尝试用 ssh 命令远程连接容器: ssh tmp@192.168.100.124
输入密码,能登录则没问题。
添加初始化容器脚本
为了方便以后初始化容器,我们将网络初始化等命令写入脚本。 在容器的 /root/ 目录执行 vim init_lxd.sh 命令创建脚本,编辑如下: # !/bin/bash
read -p "Enter your last name as the username, such as zhang: " last_name
read -p "Enter the password of the container: " password
read -p "Enter the IP address:" IP
echo "Change username to $last_name"
usermod -l $last_name -d /home/$last_name -m tmp
groupmod -n $last_name tmp
echo "Change IP to $IP"
mv /etc/netplan/50-cloud-init.yaml /etc/netplan/50-cloud-init.yaml.bak
echo "network:
version: 2
ethernets:
eth0:
dhcp4: no
dhcp6: no
addresses:
- $IP/24
gateway4: 192.168.100.254
nameservers:
addresses:
- 114.114.114.114
- 8.8.8.8" > /etc/netplan/50-cloud-init.yaml
netplan --debug apply
echo "$last_name:$password" | sudo chpasswd
reboot
安装容器的显卡驱动
容器和宿主机的显卡驱动必须保持一致,因此需要将宿主机的驱动文件传输到容器中。 因为刚安好了 ssh,因此可以选择 scp 传输。在宿主机中输入以下命令: scp ./NVIDIA-Linux-x86_64-418.56.run tmp@192.168.100.124:/home/tmp/
也可以通过 lxc 命令传输。在宿主机中输入以下命令: sudo lxc file push ./NVIDIA-Linux-x86_64-418.56.run template/home/tmp/NVIDIA-Linux-x86_64-418.56.run
以上两种方法均可传输文件。
传输后通过 ssh 进入容器,输入以下命令安装显卡驱动: sudo bash ./NVIDIA-Linux-x86_64-418.56.run --no-kernel-module
由于容器和宿主机共享内核,所以在安装容器的显卡驱动时需要添加 --no-kernel-module 参数。
安装好显卡驱动后用 nvidia-smi 命令查看显卡: 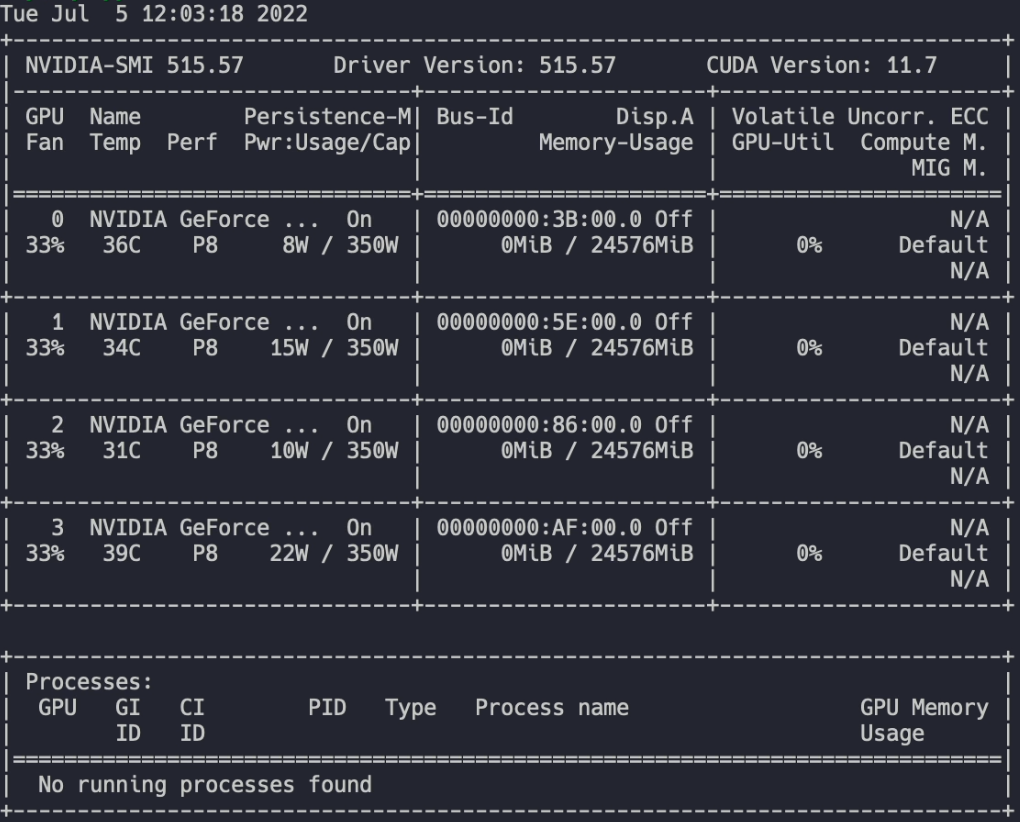
创建容器快照
在宿主机执行以下命令,对 template 容器创建一个名为 gpu 的快照: sudo lxc snapshot template gpu
创建容器脚本
现在容器模板已经制作完成,创建新的容器只需要将容器模板的快照进行复制并恢复,即可得到一个新的容器,但是命令比较复杂,因此我将其整理为脚本。 在宿主机执行 vim create_container.sh 创建脚本文件,编辑如下: # !/bin/bash
passwd='xxxx'
read -p "Enter your full name as the container name, such as zhangsan: " name
echo "Create the container $name..."
echo $passwd | sudo -S lxc copy template/gpu $name
echo "Start the container $name..."
echo $passwd | sudo -S lxc start $name
sudo -S lxc exec $name -- /bin/bash
其中 passwd 为容器的默认密码。
解决重启宿主机导致容器显卡驱动找不到的问题
此时如果重启宿主机,我们会发现容器中显卡驱动消失。目前找到的解决办法是在宿主机运行一次 pytorch cuda 的程序,并重启容器。 因此我们需要在宿主机安装 PyTorch,并在开机时自动执行 import torch; print(torch.cuda.is_available()) 命令。
安装 Anaconda
在官网下载 Anaconda3,也可以用以下命令: wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
安装Anaconda(一定不要用 sudo): bash ./Anaconda3-2022.05-Linux-x86_64.sh
Anaconda 换源(哈工大): 创建 .condarc vim ~/.condarc
编辑如下: channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.hit.edu.cn/anaconda/pkgs/main
- https://mirrors.hit.edu.cn/anaconda/pkgs/r
- https://mirrors.hit.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.hit.edu.cn/anaconda/cloud
msys2: https://mirrors.hit.edu.cn/anaconda/cloud
bioconda: https://mirrors.hit.edu.cn/anaconda/cloud
menpo: https://mirrors.hit.edu.cn/anaconda/cloud
pytorch: https://mirrors.hit.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.hit.edu.cn/anaconda/cloud
simpleitk: https://mirrors.hit.edu.cn/anaconda/cloud
运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
安装 PyTorch
在 PyTorch 官网查看对应版本的安装命令,建议创建一个新的 PyTorch 环境: conda create -n pt1.12 pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge
设置开机自启动命令
编辑 rc-local.service: sudo vim /lib/systemd/system/rc-local.service
末尾添加以下三行: [Install]
WantedBy=multi-user.target
Alias=rc-local.service
新建 rc.local
sudo vim /etc/rc.local |
编辑如下:
sleep 180s
sudo nvidia-smi -pm 1
/home/j1812/anaconda3/envs/pt1.12/bin/python -c 'import torch; print(torch.cuda.is_available())'
sudo lxc stop template --force
sudo lxc start template
exit 0
增加 rc.local 可执行权限: sudo chmod u+x /etc/rc.local
设置开机启动: sudo systemctl enable rc-local
sudo systemctl start rc-local
检查是否启动成功: sudo systemctl status rc-local
至此,已经完成了所有 LXD 的配置。
当不知道哪个容器正在占用显卡时,使用下面的命令查询:
nvidia-smi | grep -E 'python.*[0-9]{3,4}MiB' | awk '{print $5}' | xargs -I{} sh -c 'echo "PID: {} Cgroup: $(cat /proc/{}/cgroup | grep rdma | cut -d ":" -f 3)"' |
从运行 nvidia-smi 命令结果中获取占用GPU的Python进程的PID,然后通过 xargs 将PID传递给 sh 命令,进而在shell中执行一条命令来查看进程所属的 rdma 类型的cgroup。
具体来说,awk '{print $5}' 的作用是从 nvidia-smi 命令结果中获取占用GPU的Python进程的PID,其中 $5 是因为 nvidia-smi 命令结果中Python进程PID位于第5列。接着,xargs -I{} sh -c 将PID传递给 sh 命令,并在shell中执行一条命令。这条命令通过 cat /proc/{}/cgroup | grep rdma | cut -d ":" -f 3 获取进程所属的 rdma 类型的cgroup路径,并且通过 echo 命令输出PID和对应的cgroup路径。